Free T(h)r(e)ading: A Trading Systems Journey Beyond the GIL
Apr 16, 2026Originally presented at PyCon DE 2026
Python 3.13 shipped something significant: an optional free-threaded mode where the GIL is disabled and threads can run on real CPU cores simultaneously. I wanted to know whether this actually matters in practice, so I built an experiment around something I know well — algorithmic trading infrastructure.
Why Trading?
Trading systems make a good experimental subject. They’re latency-sensitive, they juggle multiple concurrent data streams, and they involve both I/O-bound work (receiving market data, routing orders) and CPU-bound work (maintaining an order book, running signal evaluation). The metrics are also concrete: you either processed the tick in time or you didn’t.
The Pipeline
The system is structured as three sequential stages:
- Market Data Receiver — pulls price and order book updates from the exchange
- Processor — applies each tick to the order book and runs a CPU-bound workload
- Evaluator — reads the latest processed state and decides whether to act
Processing is strictly sequential — ticks must be handled in order to keep the book correct. The parallelism opportunity comes from decoupling the stages so they can overlap.
I built two implementations of this pipeline: one using asyncio (three coroutines, one OS thread) and one using free-threaded CPython 3.14t (three OS threads).
The Migration
Moving from async to threaded was largely mechanical:
asyncio.Queue→queue.Queueasyncio.Event→threading.Conditionawaitcalls → blocking calls- Coroutines → regular functions passed to
threading.Thread
The trickier part was reasoning about shared state. The order book is owned exclusively by the processor thread, so it needs no locking at all. The only shared object is a single state slot where the processor writes and the evaluator reads — that gets a threading.Condition for notify/wait. One lock, one object. Lock contention turned out to be a non-issue.
What the Numbers Showed
I swept across a matrix of CPU workloads — processor time ranging from 0.5 ms to 5 ms per tick, evaluator delay from 1 ms to 50 ms — at 200 ticks/second over 60-second runs.
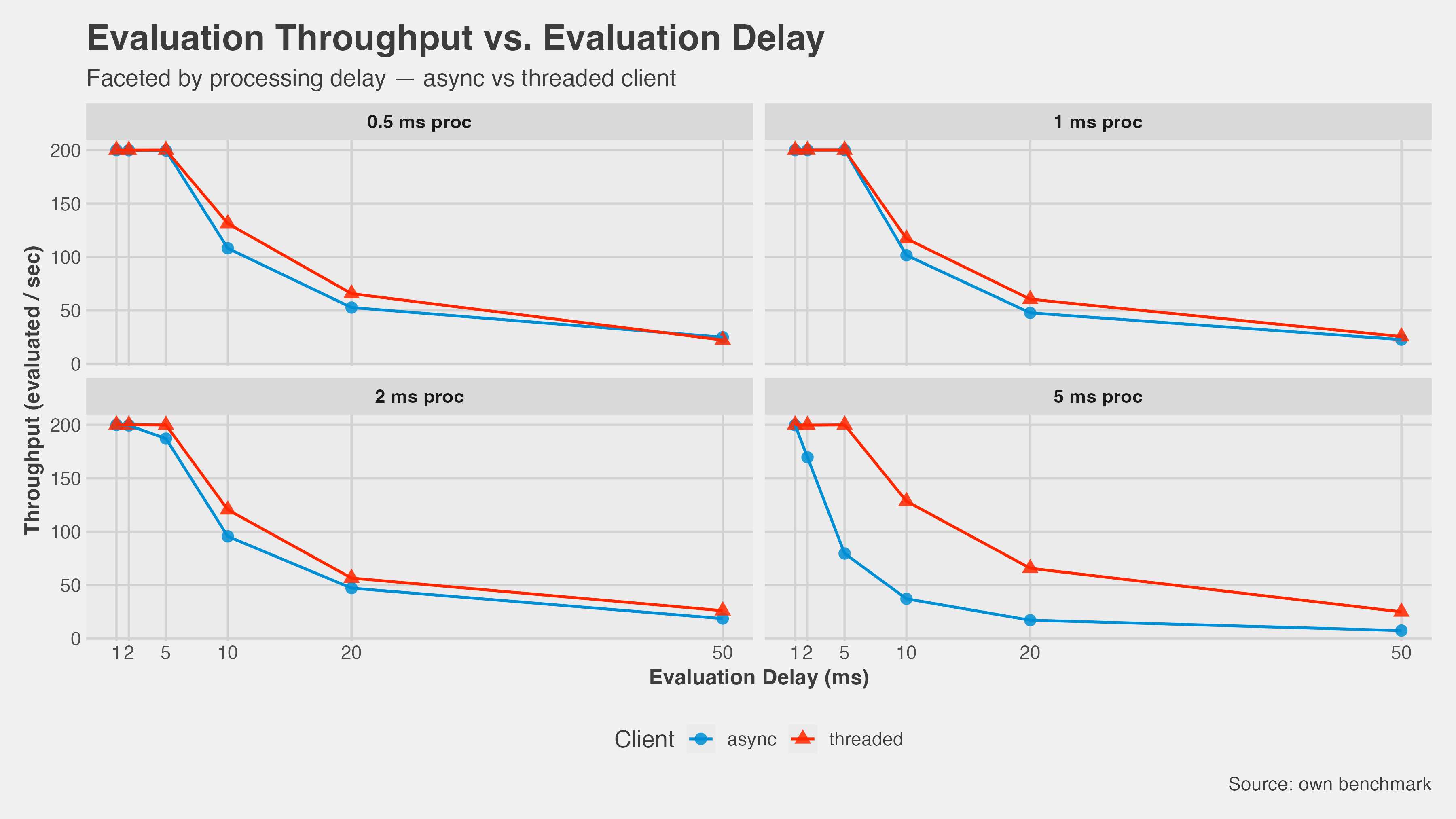
Throughput: At low processor workloads the two implementations track each other closely. As processor time climbs to 5 ms, async throughput falls off sharply while threaded stays flat. The gains were in the 47–123% range at high CPU load.
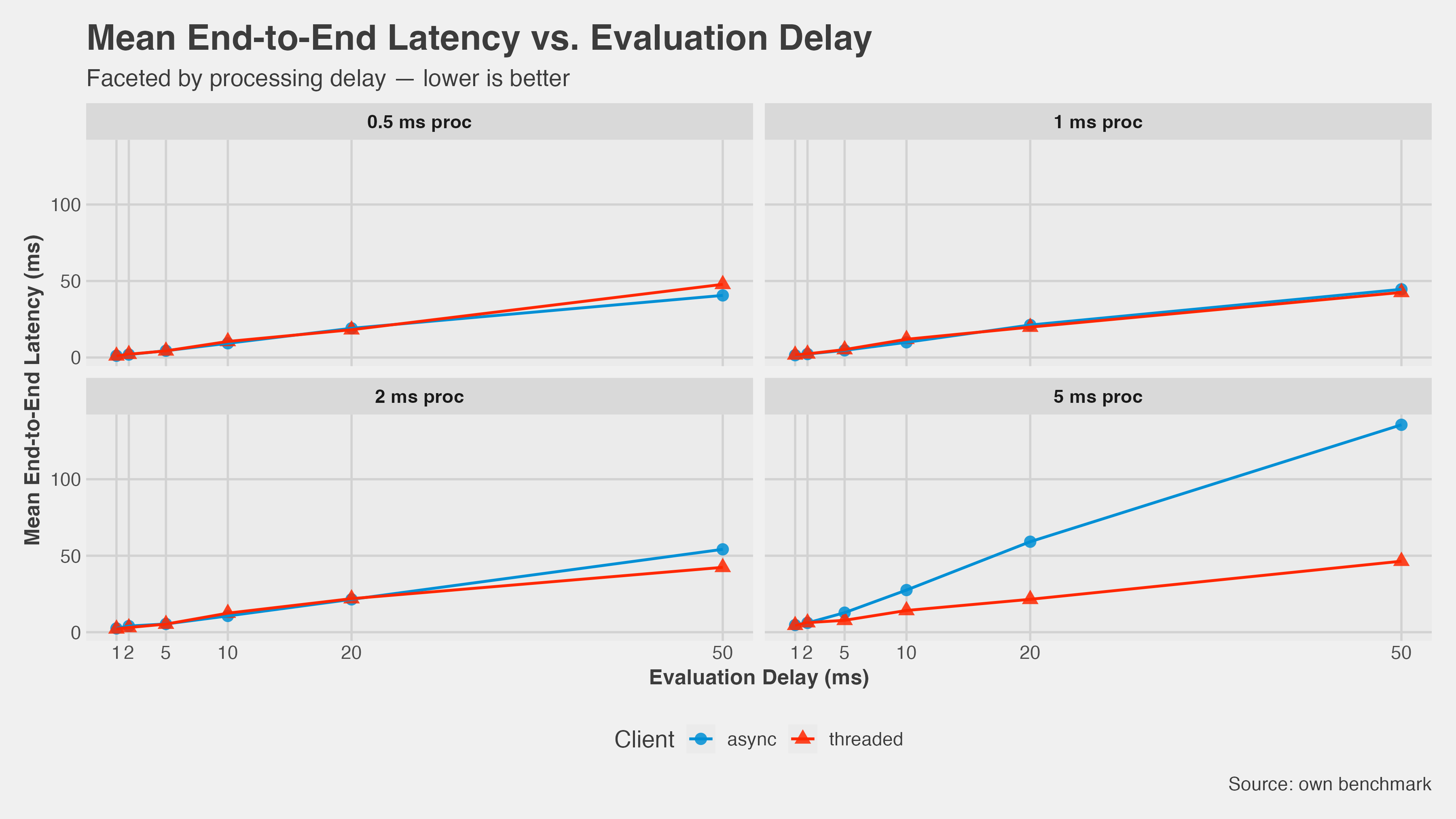
Latency: The picture is starker. At 5 ms processor time, async mean latency climbed to around 130 ms. Threaded stayed under 50 ms across every eval delay in the matrix.
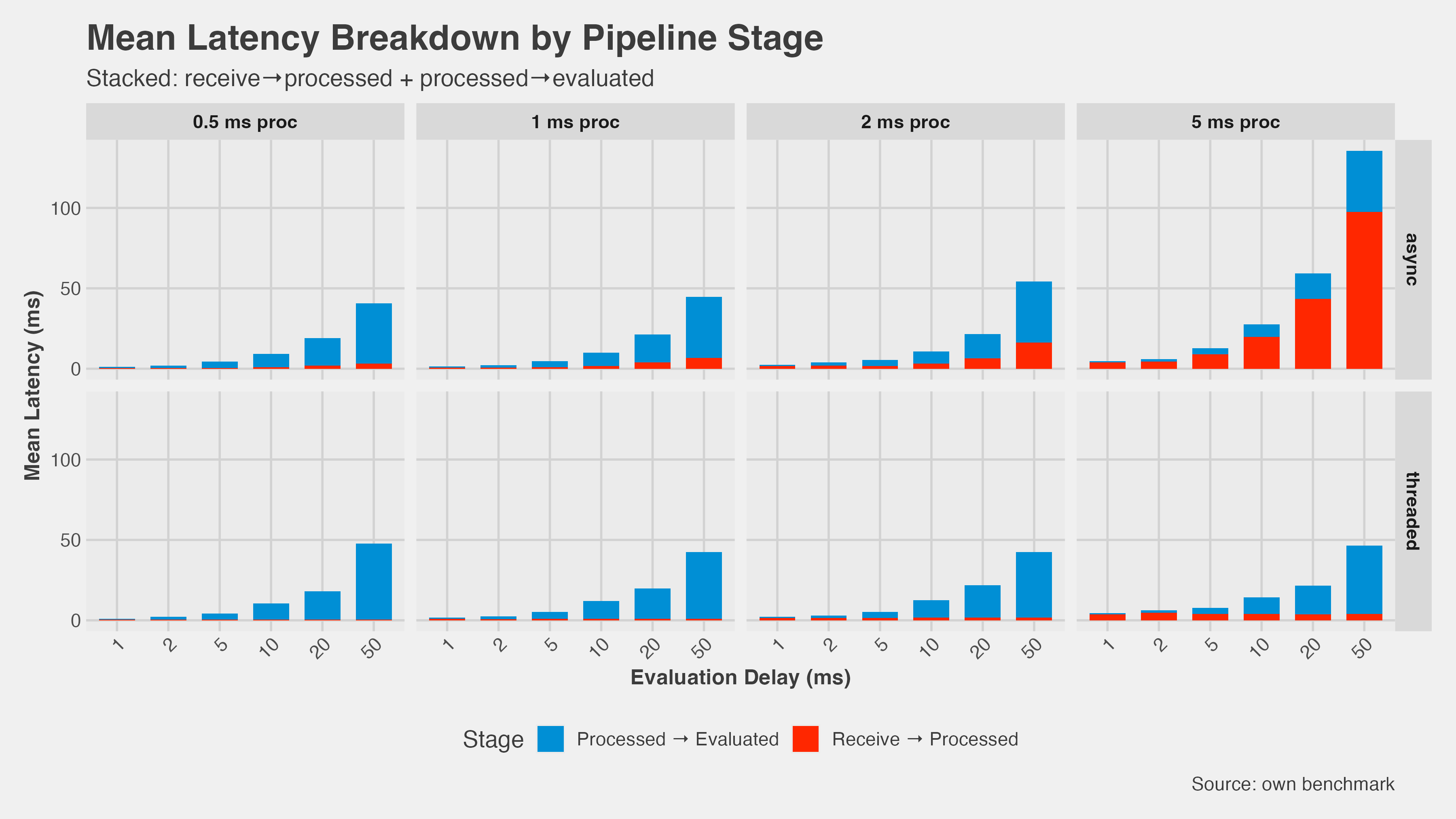
Why: In the async version, the CPU-bound processor work blocks the event loop. While it’s running, the receiver can’t pull new ticks and the evaluator can’t read the latest state. The latency breakdown makes this visible — the “receive→processed” segment dominates when CPU load is high.
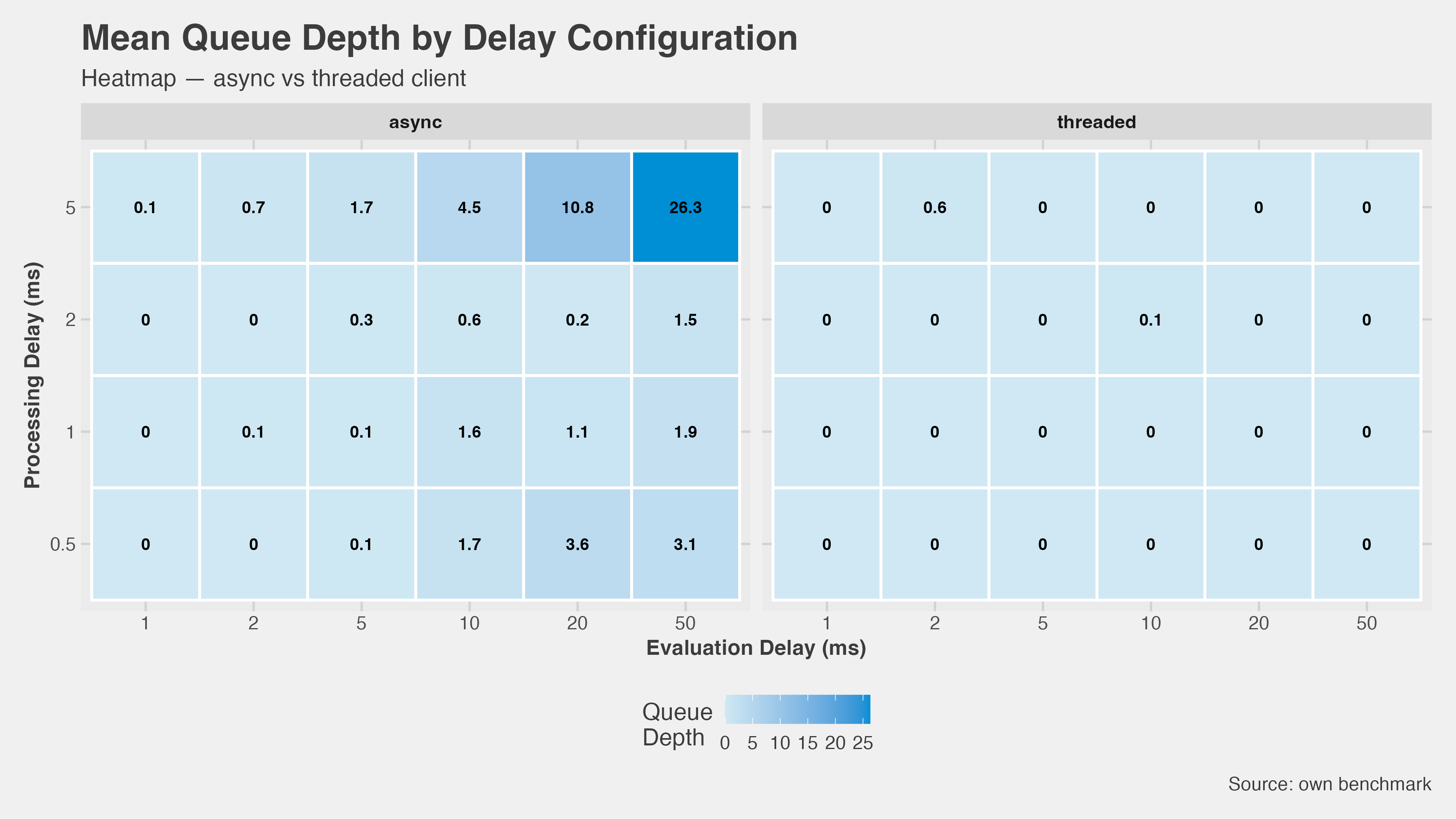
Queue depth: Async builds a backlog. At the worst-case combination (5 ms proc, 50 ms eval), the inbound queue peaked at 26 ticks. Threaded sat at zero across the entire matrix.
Revisiting the Hypotheses
Going in, I had four predictions:
- Threads beat async for CPU-bound work — Confirmed. The throughput and latency numbers both show this clearly once processor time exceeds about 1–2 ms.
- Latency improves significantly — Confirmed. The gap is large and consistent at high CPU load.
- Lock contention hurts at high tick rates — Never happened. The design avoided it: the book is never shared, and the state slot only needs one condition variable.
- There’s a crossover where async wins — Partial. The two implementations do converge at very low processor times, but even there, async never clearly beats threaded on latency.
When to Actually Use This
The default should still be asyncio. The async model is simpler, the ecosystem is more mature, and for I/O-bound workloads the performance difference is negligible.
Free-threading becomes worth considering when:
- CPU work per event is large enough that the event loop serialisation is the bottleneck
- Your pipeline has distinct stages that could genuinely run in parallel
- You’re hitting real latency walls, not theoretical ones
If you do switch, keep it simple: identify every piece of shared mutable state, give each piece exactly the synchronization it needs (often less than you expect), and keep network I/O in one thread. If you find yourself adding locks everywhere, message-passing is probably the cleaner model.
Closing Thought
The experiment confirmed what the theory predicted, but working through the actual migration made the tradeoffs concrete. Free-threaded Python isn’t a drop-in upgrade — it’s a different concurrency model with different failure modes. For CPU-bound pipelines, it’s a real option now.
The slides, code, and raw benchmark results are available on GitHub .